Identify, Block malicious network traffic with Aeternus Argus
Discover XGBoost, the state of the art model for advance classification training. Used in every field for generic purposes
Discover XGBoost, the state of the art model for advance classification training. Used in every field for generic purposes
scroll down for more information
I'm currently recruiting developers to collaborate on exciting projects. If you specialize in any of the following fields, please email me: at [email protected] I especially need a UI/UX designer, Minecraft mod developer, CS2 external/DMA developer, reverse engineering of malware, penetration testing, botnet development, or native development.
Hi, I'm Neil Huang, a software engineer and a data scientist. I'm passionate about building software and machine learning models that can help people solve real-world problems. I'm currently working on a project called Aeternus Argus, which is a network security tool that can help you identify and block malicious network traffic. I'm also a big fan of open-source software, and I love to contribute to the community whenever I can. If you have any questions or just want to chat, feel free to reach out to me on Github or LinkedIn!
I have been working as a full stack developer for over 8 years, gaining extensive experience in various programming languages including Python, C++, Java, JavaScript, TypeScript, Go, Kotlin, C, and even Scratch. My journey in software development started in lower school when i was 6 years old. I am currently ranked at the Platinum level in the USA Computing Olympiad (USACO), I find these algorithm contests really fun and they can exercise my brain. My passion for new algorithms drives me to continuously learn and innovate in the field. My expertise spans both frontend and backend development, enabling me to build comprehensive and efficient software solutions. You can explore some of my exciting projects on my GitHub profile, where I regularly contribute to open-source communities. In addition to my development work, I am also a reverse engineer and AI enthusiast. I specialize in cybersecurity and bypassing kernel-level anti-cheats and analyzing malware behavior, which involves a deep dive into system internals and security mechanisms.
Discover XGBoost, the state-of-the-art model for advanced classification training. XGBoost builds an ensemble of decision trees to deliver robust and accurate predictions, making it a favorite among data scientists.
With its efficiency and scalability, XGBoost is widely used across various industries including finance, healthcare, and marketing. This powerful model leverages gradient boosting techniques to combine weak learners into a strong predictive engine.
Explore the mechanics behind gradient boosting, decision tree ensembles, and regularization techniques that prevent overfitting. Learn how parallelization and automatic handling of missing data give XGBoost its speed and robustness.
Whether you’re just getting started or are a seasoned practitioner, the insights provided here will help you harness the full potential of XGBoost for your projects.
Explore state-of-the-art research and methods used for VPN detection and network traffic analysis.
Recent studies have explored deep learning methodologies for VPN traffic classification. Sun et al. proposed a method that transforms network traffic into images using a concept called Packet Block, which aggregates continuous packets in the same direction. These images are then processed using Convolutional Neural Networks (CNNs) to identify application types, achieving high accuracy on datasets like OpenVPN and ISCX-Tor. Read more.
Graph-based models have also been investigated for their efficacy in traffic classification. Xu et al. developed VT-GAT, a model based on Graph Attention Networks (GAT) that constructs traffic behavior graphs from raw data. This approach extracts behavioral features more effectively than traditional methods. Learn more.
Several studies have applied traditional machine learning algorithms to classify VPN traffic. Mohamed and Kurnaz, for example, used Artificial Neural Networks (ANN) to identify VPN flows, while Nigmatullin et al. combined the Differentiation of Sliding Rescaled Ranges (DSRR) approach with Random Forest classifiers, achieving high precision and recall. Read study & Learn more.
Transformer-based architectures are emerging as powerful tools for encrypted traffic classification. Lin et al. introduced ET-BERT, which pre-trains deep contextualized datagram-level representations from large-scale unlabeled data, setting new benchmarks across multiple classification tasks. Discover more.
Comparative studies have evaluated various classifiers for VPN traffic. Draper-Gil et al. assessed different algorithms using time-related features to distinguish between VPN and non-VPN traffic, offering insights into the strengths and limitations of each approach. Read the analysis.
This project is lead and developed by Neil Huang as part of the Polygence Program, within the program Maria Konte provided guidance. It focuses on developing a machine learning model to classify network traffic as either VPN or Non-VPN. Using features extracted from network flow data, the goal is to distinguish between these two types of traffic. The dataset is sourced from the ISCX VPN and Non-VPN 2016 dataset, and the model uses XGBoost with Optuna for hyperparameter optimization.
Classifying VPN traffic is important for traffic management, security, and network performance analysis. This research builds a robust classifier that differentiates between VPN and Non-VPN traffic using data-driven methods.
The dataset includes multiple scenarios (A1, A2, and B) representing different VPN and Non-VPN traffic characteristics.
The SetupData.py script automates the process of downloading, extracting, and preprocessing the data.
VPN traffic often shows more regular, predictable patterns with consistent packet and byte transfer rates. Non-VPN traffic tends to be more sporadic, with shorter bursts and irregular idle periods. By analyzing these time-based features, we can effectively differentiate between VPN and Non-VPN traffic.
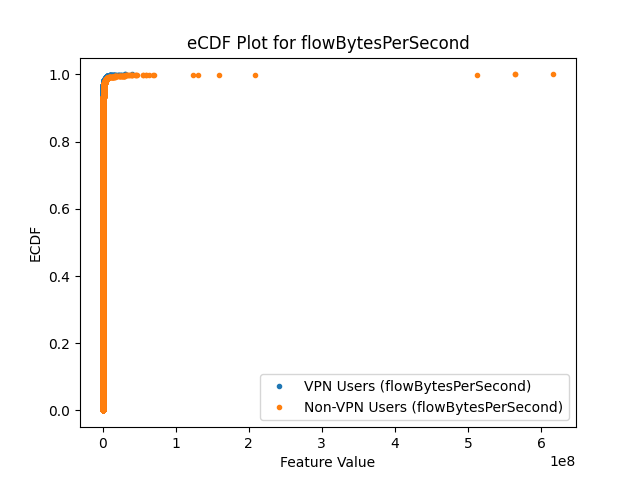
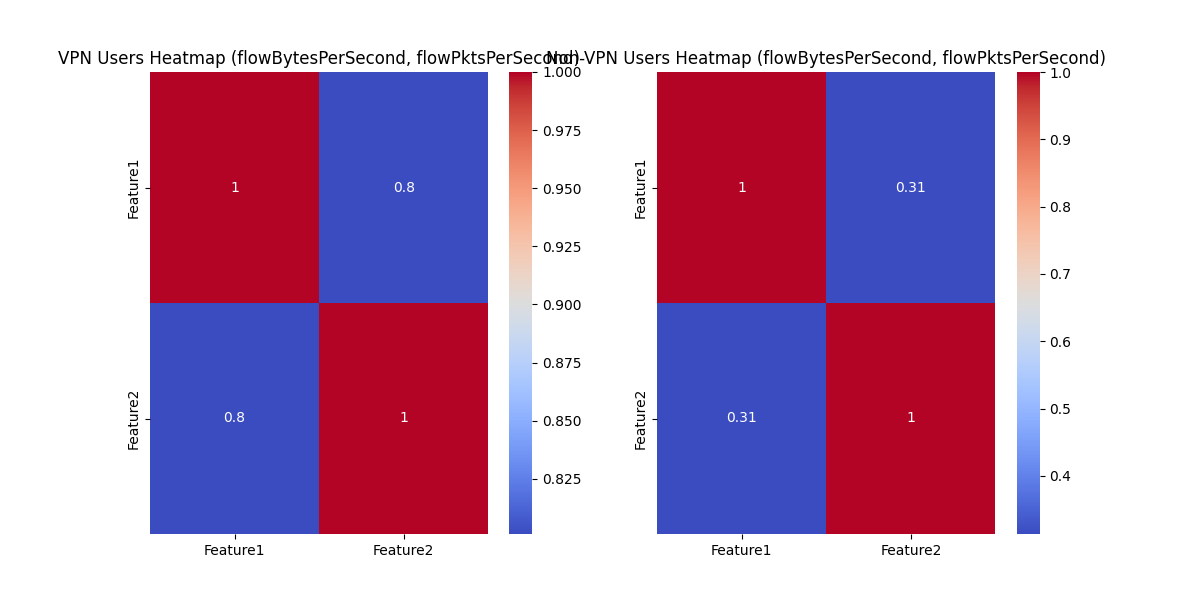
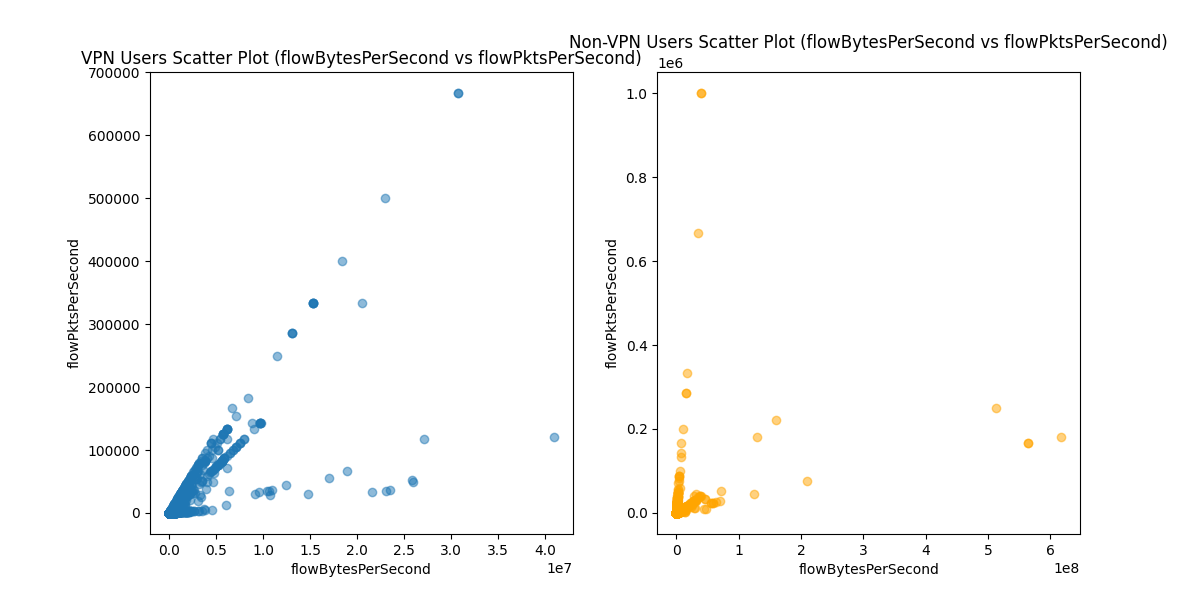
The Train.py script implements several preprocessing steps to prepare the dataset, including handling missing data, converting non-numeric columns, and using Stratified K-Fold Cross-Validation for balanced splits.
# Check for missing values
print("Missing values count:\n", df.isnull().sum())
# Drop columns with more than 50% missing data
missing_threshold = 0.5
df = df.dropna(thresh=int((1 - missing_threshold) * len(df)), axis=1)
print(f"Remaining columns after dropping columns with missing data: {df.columns}")
The script uses Optuna to automatically search for the best hyperparameters for the XGBoost model. Key parameters like n_estimators, learning_rate, max_depth, and subsample are tuned.
def objective(trial):
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 200),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1, log=True),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0),
'gamma': trial.suggest_float('gamma', 0, 10),
'min_child_weight': trial.suggest_float('min_child_weight', 1e-3, 10.0),
'reg_alpha': trial.suggest_float('reg_alpha', 1e-3, 10.0),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-3, 10.0),
'scale_pos_weight': trial.suggest_float('scale_pos_weight', 1e-3, 10.0),
}
model = XGBClassifier(**params)
fold_accuracies = []
for train_index, test_index in kf.split(df[available_features], y):
X_train = df.iloc[train_index][available_features]
y_train = y.iloc[train_index]
X_test = df.iloc[test_index][available_features]
y_test = y.iloc[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
fold_accuracies.append(acc)
return np.mean(fold_accuracies)
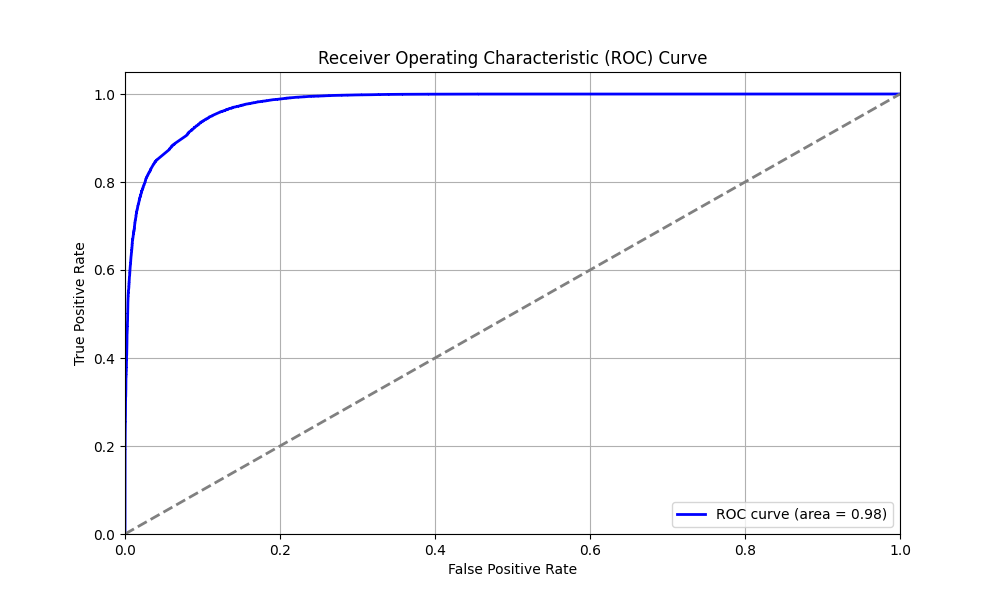
After training, the model's performance is improved by adjusting the classification threshold based on the ROC Curve to balance false positives and false negatives.
# Compute ROC curve and AUC
fpr, tpr, thresholds = roc_curve(y, model.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)
# Find the optimal threshold
optimal_threshold = thresholds[np.argmax(tpr - fpr)]
print(f"Optimal threshold: {optimal_threshold}")
# Apply optimal threshold
y_pred_optimal = (model.predict_proba(X_test)[:, 1] >= optimal_threshold).astype(int)
Before Optimization
Best trial accuracy: 0.8983698375392972
Best parameters: (see snippet below)
Best trial accuracy: 0.8983698375392972
Best parameters: {'n_estimators': 137, 'learning_rate': 0.056998467188966166, 'max_depth': 10, 'subsample': 0.6885374473966026, 'colsample_bytree': 0.8316744476524894, 'random_state': 28, 'gamma': 6.846816972984089, 'min_child_weight': 1.9011750589572292, 'reg_alpha': 8.788661748447671, 'reg_lambda': 9.17186993955007, 'scale_pos_weight': 1.5367434543465421, 'max_delta_step': 8, 'colsample_bylevel': 0.8977692687002093, 'colsample_bynode': 0.6884480938017858}
After Optimization
Best trial accuracy: 0.9093782145477146
This ~2% improvement in accuracy is significant, indicating that threshold tuning and parameter optimization help the model generalize better.
Best trial accuracy: 0.9093782145477146
Best parameters: {'n_estimators': 153, 'learning_rate': 0.06057883562221319, 'max_depth': 10, 'subsample': 0.7267015030731455, 'colsample_bytree': 0.6631537892477964, 'random_state': 17, 'gamma': 2.368698710253576, 'min_child_weight': 8.637108660931315, 'reg_alpha': 9.630173474548245, 'reg_lambda': 0.14523433378303974, 'scale_pos_weight': 3.7039133272302873, 'max_delta_step': 10, 'colsample_bylevel': 0.6220516152279684, 'colsample_bynode': 0.5067381656563739, 'threshold': 0.6872133792668326}
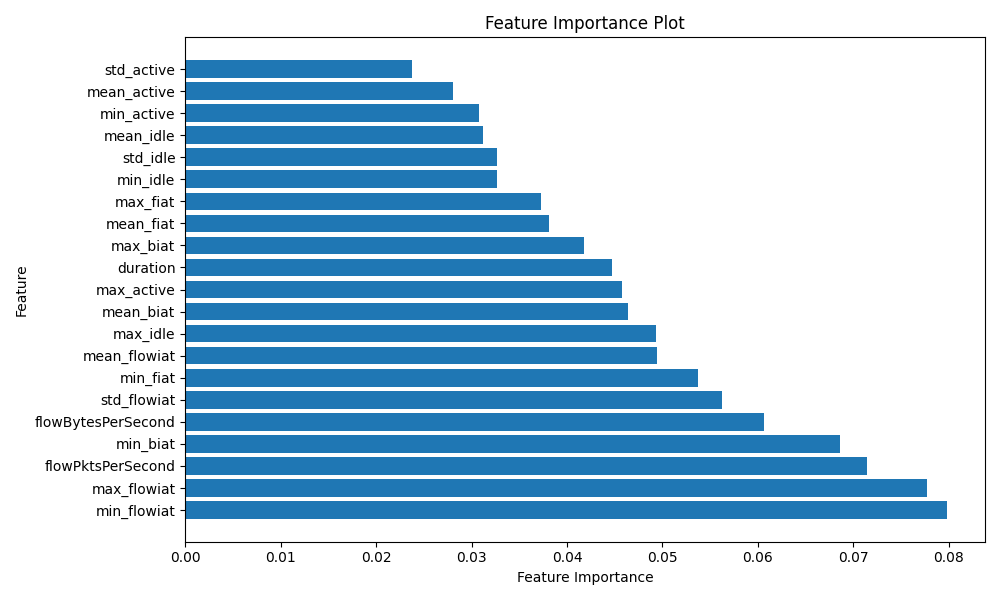
The optimized model now focuses more on key features and yields better performance. Regularization and threshold optimization both contributed to reducing false positives and improving overall accuracy.
We welcome contributions to improve this project! If you’d like to contribute, please see the GitHub repository for detailed instructions on forking, creating new branches, making changes, and submitting pull requests.